
Harvard Art Museum Data Preparation in Python
A project that uses Python to pull data through API to generate a dataset for further projects.
The code below displays highlights from the project. For more details, please view the GitHub Repository.
Link to GitHub Repository:
Libraries
import json
import urllib3
import pandas as pd
from pandas import DataFrame
import datetime as dt
import numpy as np
API Request to pull 99 entries of any art description containing the word “dog”
API_KEY = '###'
http = urllib3.PoolManager()
r = http.request('GET', 'https://api.harvardartmuseums.org/object',
fields = {
'apikey': API_KEY,
'title': 'dog',
'size': 99
})
Load API request into JSON format
data_2 = json.loads(r.data)
Verify that the variables can be called
for record in data_2["records"]:
print(record['provenance'])

Create a list that pulls only the needed variables for the project
all_data = []
for record in data_2["records"]:
data_dict = {}
data_dict['Title'] = record["title"]
data_dict['Date_Begin'] = record["datebegin"]
data_dict['Total_Page_Views'] = record["totalpageviews"]
data_dict['Technique_ID'] = record["techniqueid"]
data_dict['Provenance'] = record["provenance"]
data_dict['Century'] = record["century"]
data_dict['Object_ID'] = record["objectid"]
data_dict['Accession_Method'] = record["accessionmethod"]
data_dict['Period'] = record["period"]
data_dict['Rank'] = record["rank"]
data_dict['Edition'] = record["edition"]
data_dict['Culture'] = record["culture"]
data_dict['Signed'] = record["signed"]
data_dict['Date_Of_Last_Page_View'] = record["dateoflastpageview"]
data_dict['Style'] = record["style"]
data_dict['Technique'] = record["technique"]
data_dict['Date_End'] = record["dateend"]
all_data.append(data_dict)
Convert data to a Pandas dataframe so it is in a readable and usable format
df = DataFrame(all_data)
df
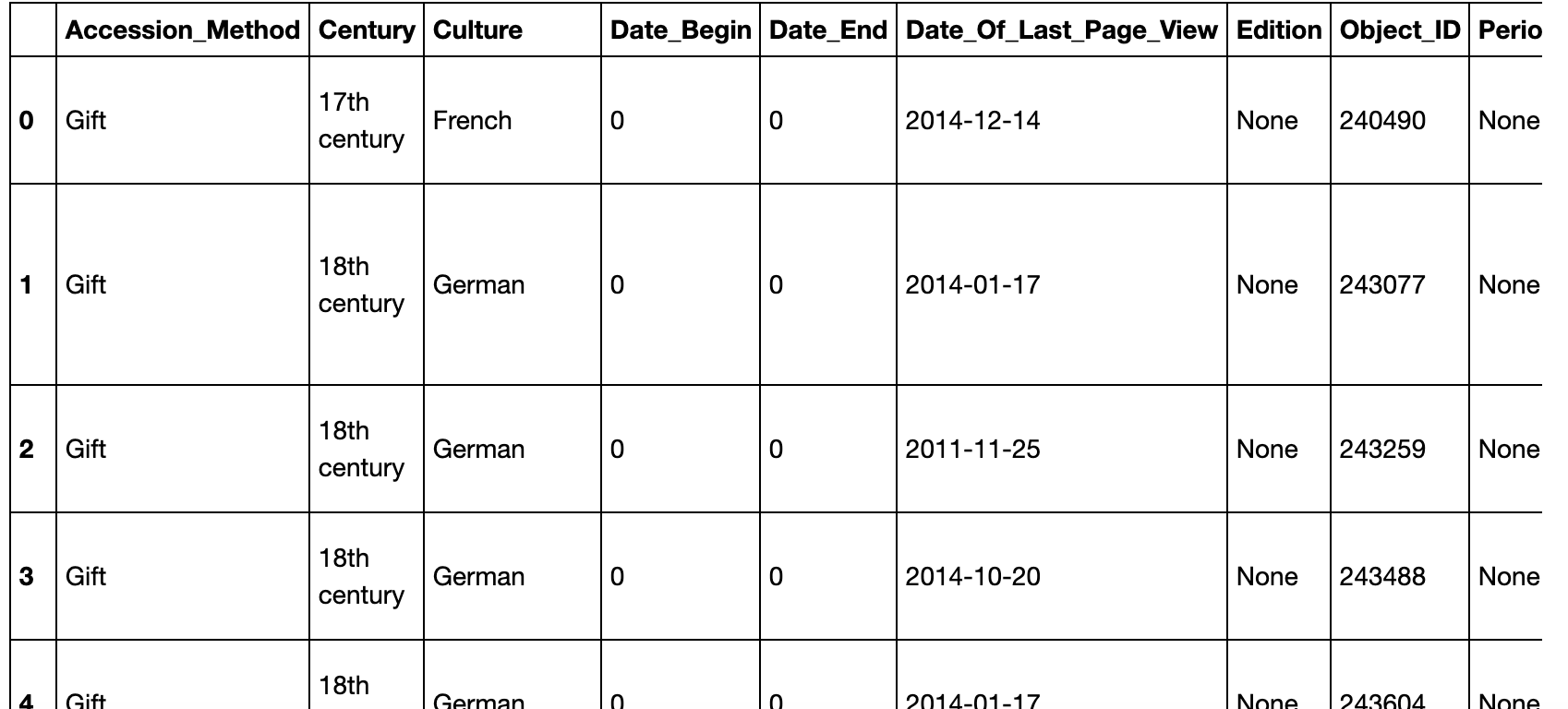
Reformat Date of Last Page View
# Convert column values to date format
df['Date_Of_Last_Page_View'] = pd.to_datetime(df.Date_Of_Last_Page_View)
# Create new column in dataframe with date in updated format
df['Date_Of_Last_Page_View_String'] = df['Date_Of_Last_Page_View'].dt.strftime('%m/%d/%Y')
df
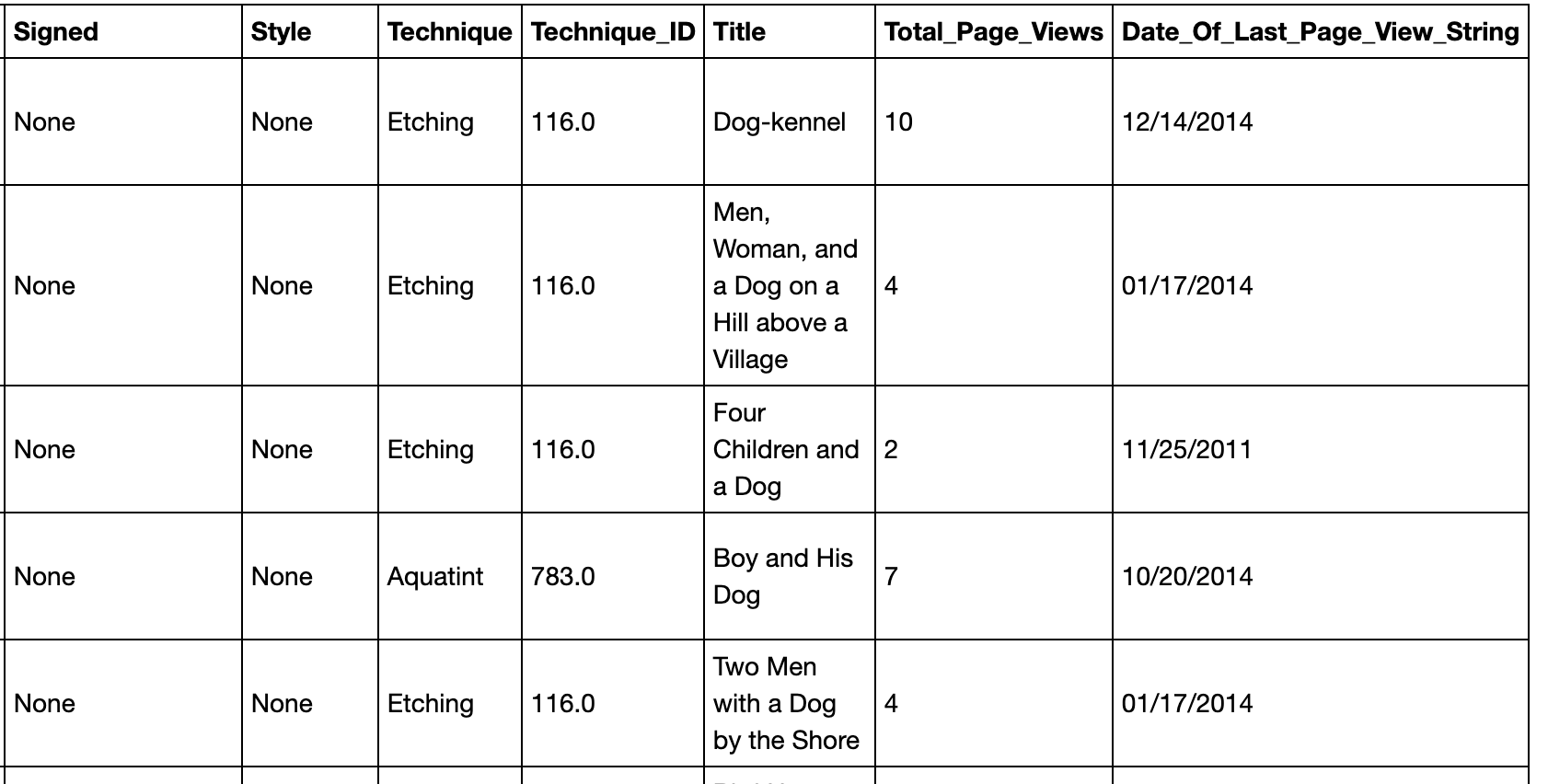
Reformat Technique ID
# The technique ID has an extra .0 at the end which is unnecessary
# First, remove the NAN values in that column
df = df[pd.notnull(df['Technique_ID'])]
# Next, convert the variable to a string that removes the .0 at the end
df['Technique_ID'] = df['Technique_ID'].astype(str).replace('\.0', '', regex=True)
# Convert variable back to integer
df['Technique_ID'] = df['Technique_ID'].astype(int)
df
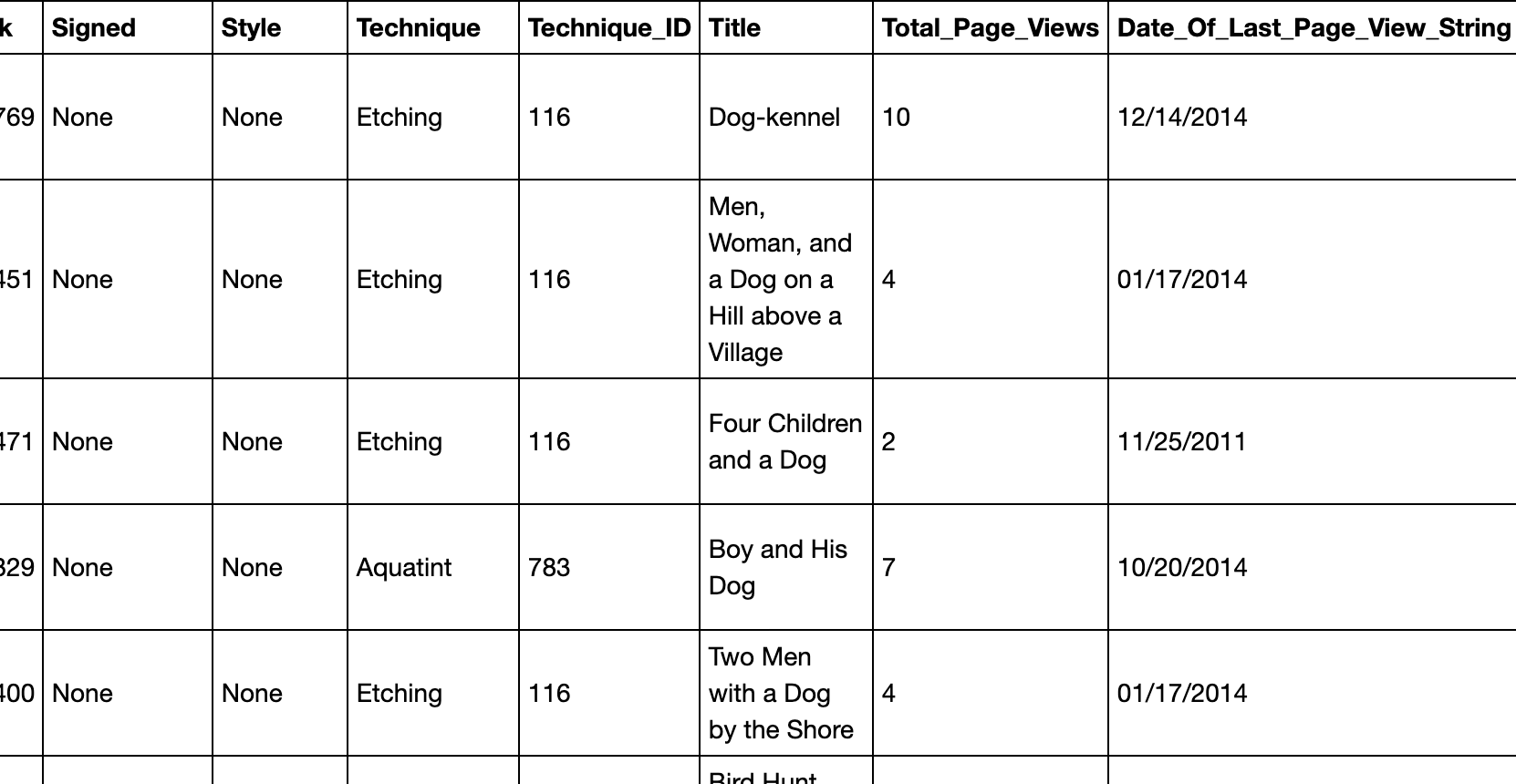
Export to CSV
df.to_csv(r'Formatted_dataset.csv')